接近一年没有更新博客了,这是 2020 的第一篇,源于对基础知识的巩固,主要会从多个维度解释字符编码的由来以及内部原理。
大家都知道,程序中的所有信息都是以二进制的形式存储在计算机的底层,也就是说我们在代码中定义的一个 char 字符或者一个 int 整数都会被转换成二进制码储存起来,这个过程可以被称为编码,而将计算机底层的二进制码转换成屏幕上有意义的字符(如“hello world”),这个过程就称为解码。
在计算机中字符的编解码就涉及到字符集(Character Set)这个概念,他就相当于能够将一个字符与一个整数一一对应的一个映射表,常见的字符集有 ASCII、Unicode 等。
很多时候我们会将字符集的编码与字符集混为一谈,从这里就可以看出它们并非同一个概念,字符集仅仅是一个字符的集合,而编码却是一个更复杂的过程。至于为什么会经常将这两个概念放在一起,他们之间的联系是什么,我们经常使用的 UTF-8 又是什么,这就是这篇文章我要讨论的话题。
ASCII 编码
历史中的很长一段时间里,计算机仅仅应用在欧洲的一些发达国家,因此在他们的程序中只存在他们所理解的拉丁字母(如a、b、c、d等)和阿拉伯数字,他们在编码解码时也只需要考虑这一种情况,就是如何将这些字符转换成计算机所能理解的二进制数,此时 ASCII 字符集应运而生,他们在编码时只需要对照着 ASCII 字符集,每当在程序中遇到字符 a 时,就会相应的找到其中 a 对应的 ASCII 值 97 然后以二进制形式存起来即可。
下图展示了 ASCII 字符集对照表,其中包括了控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
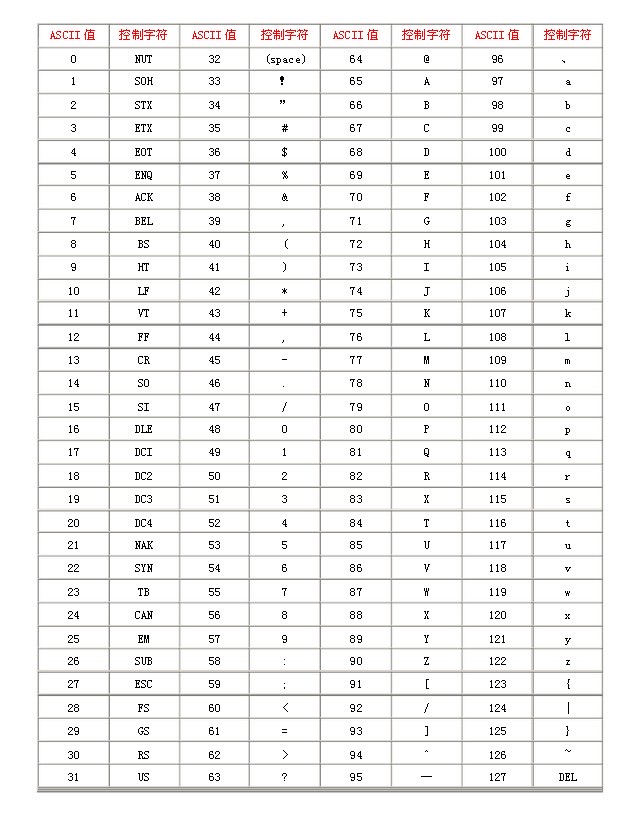
这种编码方式就被称为 ASCII 编码,从字符集对照表中可以看出,ASCII 字符集支持 128 种字符,仅使用 7 个 bit 位,也就是一个字节的后 7 位就可以将它们全部表示出来,而最前面的一位统一规定为 0 即可(如 0110 0001 表示 a)。
后来,为了能够表示更多的欧洲国家的常用字符如法语中带符号的字符 é,又制定了 ASCII 额外扩展的版本 EASCII,这里就可以使用一个完整子节的 8 个 bit 位表示共 256 个字符,其中就又包括了一些衍生的拉丁字母。
非 ASCII 编码
ASCII 字符集沿用至今,但它最大的缺点在于只能表示基本的拉丁字母、阿拉伯数字和英式标点符号,因此只能表示现代美国英语(而且在处理英语当中的外来词如 naïve、café、élite 等等单词时,所有重音符号都不得不去掉)。而 EASCII 虽然解决了部份西欧语言的显示问题,但是当计算机传入亚洲之后,各国的语言依然不能完整地表示出来。
在这个年代,每个国家就各自来对 ASCII 字符集做了拓展,最具代表性的就是国内的 GB 类的汉字编码模式,这种模式规定:ASCII 值小于 127 的字符的意义与原来 ASCII 集中的字符相同,但当两个 ASCII 值大于 127 的字符连在一起时,就表示一个简体中文的汉字,前面的一个字节(高字节)从 0xA1 拓展到 0xF7,后面一个字节(低字节)从 0xA1 到 0xFE,这样就可以组合出了大约 7000 多个简体汉字了。
为了在解码时操作的统一,GB 类编码表中还也加入了数学符号、罗马希腊的字母、日文的假名等,连在 ASCII 里本来就有的数字、标点、字母都统一重新表示为了两个字节长的编码,这就是我们常说的 “全角” 字符,而原来在 127 号以下的那些就叫 “半角” 字符了,这种编码规则就是后来的 GB2312。
“一个汉字算两个英文字符!一个汉字算两个英文字符……”
下图展示了 GB2312 字符集中的一小部分,具体可查看 GB2312 简体中文编码表。
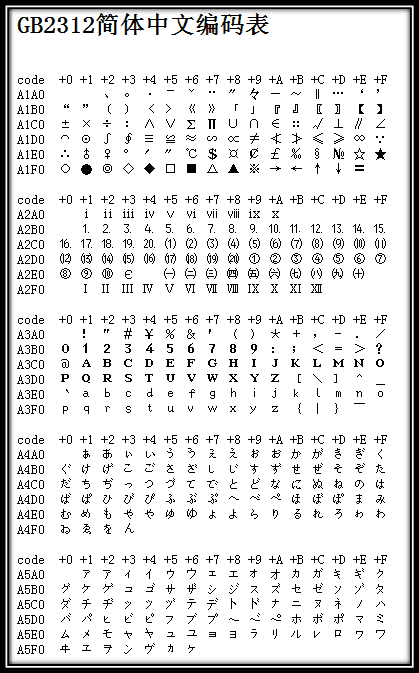
这样,我们中国就有了属于自己的字符集了,但中国的汉字又实在是太多了,人们很快就发现 GB2312 字符集只能够那点汉字明显不够(如中国前总理朱镕基的 “镕” 字并不在 GB2312 字符集中),于是专家们又继续把 GB2312 没有用到的码位使用到其他没有被收录的汉字中。
后来还是不够用,于是干脆不再要求低字节一定是 127 号之后的内码,只要第一个字节是大于 127 就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近 20000 个新的汉字(包括繁体字)和符号。
当时的各个国家都像中国这样制定出了一套自己的编码标准,之后当我们需要使用计算机与国际接轨时,问题出现了!国家与国家之间谁也不懂谁的编码,130 在法语编码中代表了 é,在希伯来语编码中却代表了字母 Gimel (ג),在俄语编码中又会代表另一个符号。但是所有这些编码方式中,0–127 表示的符号依然都是一样的,因为他们都兼容 ASCII 码,这一点,如今也是一样。
Unicode
正如上一节中所说的,世界上各国都有不同的编码方式,同一个二进制数字可以被解码成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为了解决这个问题,最终的集大成者 Unicode 字符集出现了,它将世界上所有的符号都纳入其中,成功实现了每个数字代表唯一的至少在某种语言中使用的符号,目前,Unicode 字符集中已经收录超过 13 万个字符(第十万个字符在2005年获采纳)。值得关注的是,Unicode 依然兼容 ASCII,即 0~127 意义依然不变。
码点
Unicode 表示的是一个字符集,与我们通常所说的 UTF-8、UTF-6 等编码方式并不相同,本节介绍的编号就相当于 ASCII 码中的 ASCII 值,它就是 Unicode 字符集中唯一表示某个字符的标识,在 Unicode 也称作码点(Code Point),如码点 U+0061,这里的 61 就是 97 的十六进制表示,它就表示 Unicode 字符集中的字符 ‘a‘。
码点的表示的形式为 U+[XX]XXXX,X 代表一个十六制数字,一般可以有 4-6 位,不足 4 位前补 0 补足 4 位,超过则按是几位就是几位,具体范围是 U+0000~U+10FFFF,大概是 111 万。按 Unicode 官方的说法,码点范围就这样了,以后也不扩充了,一百多万足够用了,目前也只定义了 11 万多个字符左右。
整个编码过程中码点就作为了一个中间的过渡层,可用下面这张图来表示:
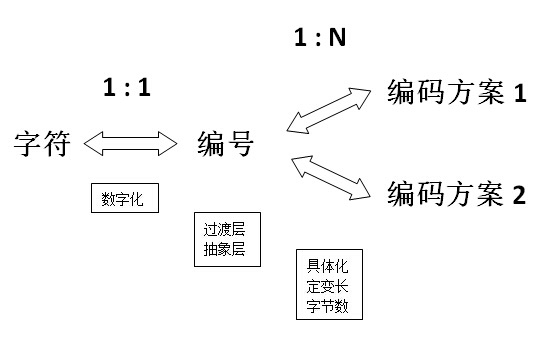
从这张图可以看出,整个解码可分为两个过程。首先,将程序中的字符根据字符集中的编号数字化为某个特定的数值,然后根据编号以特定的方式存储到计算机中。
显然,这时候我们就可以发现编号并不是最终存储在计算机中的结果。按照之前的理解,编码即把一个字符编码为一个二进制数字存储起来,然而这种表述并不准确,真正的编码不止这么简单,这其中还涉及了每个数字用几个字节表示,是用定长还是变长表示等具体细节。
举个例子,字符 a 的码点为 U+0061(十进制为 97),那么这个 U+0061 该如何存储,单纯的表示 U+0061 可以直接使用 7 位的二进制数 110 0001 表示,但在 GB 类的编码模式中就需要以两个字节存储即 0000 0000 0110 0001(空位用 0 填充)。
Unicode 编码
Unicode 字符集衍生出来的编码方案有三种,分别是 UTF-32、UTF-16 和 UTF-8,这使他与之前的编码模式不同,因为 ASCII、GBK 等类编码模式的字符集和编码方式都是一一对应的,而 Unicode 的编码实现却有三种,这就是我们需要区分字符集与编码的原因之一,因为此时 Unicode 并不特指 UTF-8 或者 UTF-32。
下面,我们来看下面这张示意图,探究各种编码模式下,码点是如何具体转换成各种编码的:

上面表中包含了四个字符的码点,其中也展示了四个不同的码点在 UTF-32、UTF-16 和 UTF-8 三种编码模式下的编码结果。其中:码点到 UTF-32 的转换最简单,就是在前面填充 0 满 4 字节即可;码点到 UTF-8 的转换,除了最小那个在数值上一样外,其它三个完全看不出两者的关系;码点到 UTF-16 的转换则是最不规则的,可以看出前三个字符 UTF-16 与码点是完全一致的,但那个大码点(准确地说是超过了 U+FFFF 的码点)则有了很大的变化,长度变成了四字节,值也变得很不一样了。
这其中又涉及到编码过程中定长与变长两种实现方式,这里的 UTF-32 就属于定长编码,即永远用 4 字节存储码点,而 UTF-8、UTF-16 就属于变长存储,UTF-8 根据不同的情况使用 1-4 字节,而 UTF-16 使用 2 或 4 字节来存储码点。
定长于变长
为什么要有定长于变长这两种编码形式?在中文的表达中都会有所谓的断句问题,如果我们处理不好断句很有可能会将意思传递错误。如下面这句来自算命先生纸条中的内容:
大富大贵没有灾难要小心
此时,如果算命侠客这样断句:
大富大贵,没有灾难要小心
表示我福大命大,没有灾难,可以肆意妄为了,但是没过多久这位侠客就去世了,算名先生绝望地说,你会错意了,原来,其实是这样断句的:
大富大贵没有,灾难要小心
表示你没有大富大贵,出门要小心,断句就可能会出现这样严重的后果。
这也是计算机在解码时需要使用定长与变长的原因。因为计算机底层的二进制码也和算命先生纸条中的内容一样,毫无章法,我们如果想要正确理解其中的意思就要有一个约定俗成的规则。
UTF-32
在 UTF-32 这种定长的编码方式下就表示每 4 个子节一个断句,那么字符 A 的码点 U+0041(二进制为 1000001)被 UTF-32 编码后就会变成如下形式存储在计算机中:
00000000 00000000 00000000 01000001
它会将 4 个字节中空出的高位全部填充为 0。这种表示的最大缺点是占用空间太大,因为不管都大的码点都需要四个字节来存储,非常的占空间,那么如何突破这个瓶颈呢?变长方案应运而生。
UTF-8
UTF-8 属于变长的编码方式,它可以由 1,2,3,4 四种字节组合,使用的是高位保留的方式来区别不同变长,具体方式如下:
对于只有一个字节的符号,字节的第一位设为
0,后面 7 位为这个符号的 Unicode 码。此时,对于英语字母UTF-8 编码和 ASCII 码是相同的。对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码,如下表所示:
| Unicode 码点范围(十六进制) | UTF-8 编码方式(二进制) | 字节数 |
|---|---|---|
| 0000 0000 ~ 0000 007F | 0xxxxxxx | 一个字节 |
| 0000 0080 ~ 0000 07FF | 110xxxxx 10xxxxxx | 二个子节 |
| 0000 0800 ~ 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 三个字节 |
| 0001 0000 ~ 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 四个字节 |
跟据上表,编码字符时就非常简单了,以汉字 “丑” 为例,它的码点为 0x4E11(0100 1110 0001 0001)在上表的第三行范围(0000 0800 ~ 0000 FFFF)内,因此 “丑” 需要以三个字节的形式编码:
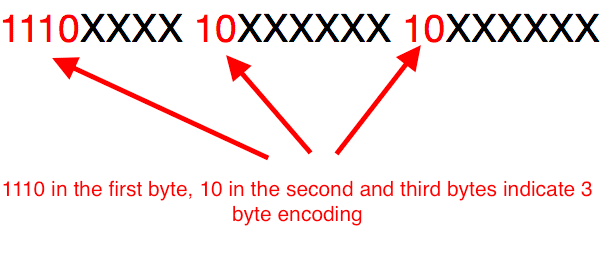
这里最高位的第一个字节中的三个 1 表示该字符占 3 个字节,空出的 16 位 x 就会从 “丑” 的最后一个二进制位开始,依次从后向前填入格式中,多出的位补 0,这样就得到了 “丑” 的 UTF-8 编码是 11100100 10111000 10010001,转换成十六进制就是 E4B891。
解码 UTF-8 编码也很简单了,如果一个字节的第一位是 0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个 1,就表示当前字符占用多少个字节,”丑” 有三个 1 表示占三个字符,然后取出有效位即可。
UTF-16
UTF-16 使用的是一种变长为 2 或 4 字节编码模式。
最初,Unicode1.0 被设计为纯 16 位编码,拥有 65,536 个码点(U+0000~U+FFFF),目的就是希望能够表示所有现代字符,然而随着时间推移,16 位对于计算机而言显然是不够的,因此产生了如今的 4 字节的 UTF-16 编码,此时,Unicode 就具有了 1,114,112 个代码点(U+10000 ~ U+10FFFF),这就是我们之前介绍 Unicode。
此时,范围在 U+0000~U+FFFF 的码点被称了为 BMP(Basic Multilingual Plane,基本多语言平面),而后来拓展的范围 U+10000 ~ U+10FFFF 称为 SP(Supplementary Planes,增补平面)。UTF-16 就是利用 BMP 使用代理的方式来对字符进行编码。
何为代理?
代理和 UTF-8 中的高位保留的目的一样,就是为了能够实现变长的编码方式。
什么是代理区?
代理区由两个特殊范围(BMP 中的空闲部分)的 Unicode 码点组成,总共有 2048 个位置,均分为高代理区(D800–DBFF)和低代理区(DC00–DFFF)两部分,各 1024,这两个区可以组成一个二维的表格,共有 1,024 x 1,024 = 1,048,576 = 16×65536 个单元格,所以它恰好可以表示代理(增补)的 16 位中的所有字符。

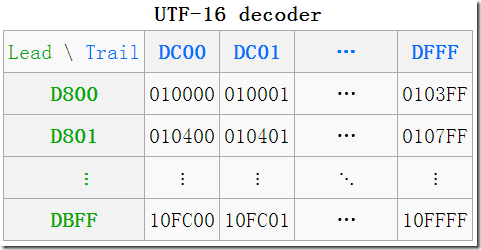
这种从一维存储转换到二维存储的方式就可以实现空间增大的效果了,UTF-16 也就有了能够额外获得码点的方式了。
一个高代理区(即上图中的 Lead(头),行)的加一个低代理区(即上图中的Trail(尾),列)的编码组成一对代理对(Surrogate Pair)。在图中就可以看到一些转换的例子,如
(D8 00 DC 00)—>U+10000,左上角,第一个增补字符
(DB FF DF FF)—>U+10FFFF,右下角,最后一个增补字符
从 UTF-16 转换为字符代码的算法是什么?
分成两部分:
BMP 中直接对应,无须做任何转换;
增补平面 SP 中,则需要做相应的计算。其实由上图中的表也可看出,码点就是从上到下,从左到右排列过去的,所以只需做个简单的除法,拿到除数和余数即可确定行与列。
拿到一个码点,先减去 10000,再除以 400(=1024)就是所在行了,余数就是所在列了,再加上行与列所在的起始值,就得到了代理对了。
$$
C_H =(码点 – 10000_{16})\div 400_{16} + D800_{16}
$$
$$
C_L =(码点 – 10000_{16})% 400_{16} + DC00_{16}
$$
需要关注的是,最常用的字符依然是在 BMP 平面中编码的,下表给出了各码点范围内 UTF-16 编码取值方法:
| Unicode 码点范围 | UTF-16 编码 |
|---|---|
| U+0000..U+D7FF | BMP内,一个字节,不做转换 |
| U+D800..U+DFFF | BMP 空闲区 |
| U+E000..U+FFFF | BMP内,一个字节,不做转换 |
| U+10000..U+10FFFF | 两个字节: 高位+低位 |
下面以码点 U+1D11E 具体示例计算代理对:
$$
高代理 = (1D11E – 10000_{16}) ÷ 400_{16} + DB00 = D11E ÷ 400_{16} + D800 = 34 + D800 = D834
$$
$$
低代理 = (1D11E – 10000_{16}) % 400_{16} + DC00 = D11E % 400_{16} + DC00 = 11E + DC00 = DD1E
$$
所以,码点 U+1D11E 对应的代理对即是 D834 DD1E。下表又列举出了其他字符的 UTF-16 的编码过程:
| 字符 | 码点 | Unicode 二进制编码 | UTF-16 代码单元 | UTF-16 十六进制字节 |
|---|---|---|---|---|
| $ | U+0024 | 0000 0000 0010 0100 | 0000 0000 0010 0100 | 0024 |
| € | U+20AC | 0010 0000 1010 1100 | 0010 0000 1010 1100 | 20AC |
| [𐐷 | U+10437 | 0001 0000 0100 0011 0111 | 1101 1000 0000 0001 1101 1100 0011 0111 | D801 DC37 |
| 𤭢 | U+24B62 | 0010 0100 1011 0110 0010 | 1101 1000 0101 0010 1101 1111 0110 0010 | D852 DF62 |
和 UTF-8 中高位保留的方式一样,UTF-16 在各码点范围内同样拥有一个二进制到实际编码单元的映射表,如下:
| Codepoint range | Unicode 二进制 | UTF-16 编码方式(代码单元) |
|---|---|---|
| U+0000 ~ U+D7FF,U+E000 ~U+EFFF | 00000xxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxx |
| U+10000 ~ U+10FFFF | Uuuuuxxxxxxyyyyyyyyyy | 110110wwwwxxxxxx 110111yyyyyyyyyy |
按照上面的两个表我们也不难发现其中的规律,在 U+10000 ~ U+10FFFF 范围内的码点在编码时可以分别将第一个子节和第三个字节的高位设为 110110 和 110111,然后再根据 Unicode 二进制码各位填补即可(其中,这里的uuuuu = wwww + 1)。
本篇到此结束,大家有任何问题可直接联系我,也可在博客评论区讨论。
参考文章以及衍生阅读
Mapping codepoints to Unicode encoding forms
General questions, relating to UTF or Encoding Form

