本文翻译自:Busting Android performance myths,作者:Calin Juravle,译文首次发表于微信公众号「Meandni」,点击阅读。
近年来,社区充斥着关于 Android 性能优化的各种误区,本文本着误区终结者的精神,使用具体的性能检测工具,结合真实案例仔细分析这些情况,并对比它们的测试结果,也会聚焦 Android 开发者平时在编码过程的实际场景,用实际数据告诉你在实际编码之前请,一定要进行必要的性能检测。
误区1:Kotlin 比 Java 更消耗性能
Google 云端硬盘团队目前已将其应用程序从 Java 全面替换为 Kotlin,重构范围涉及 170 多个文件,超过 16,000 行代码,包含 40 多个编译产物,在团队监控的指标中,第一要素是启动时间,测试结果如下:
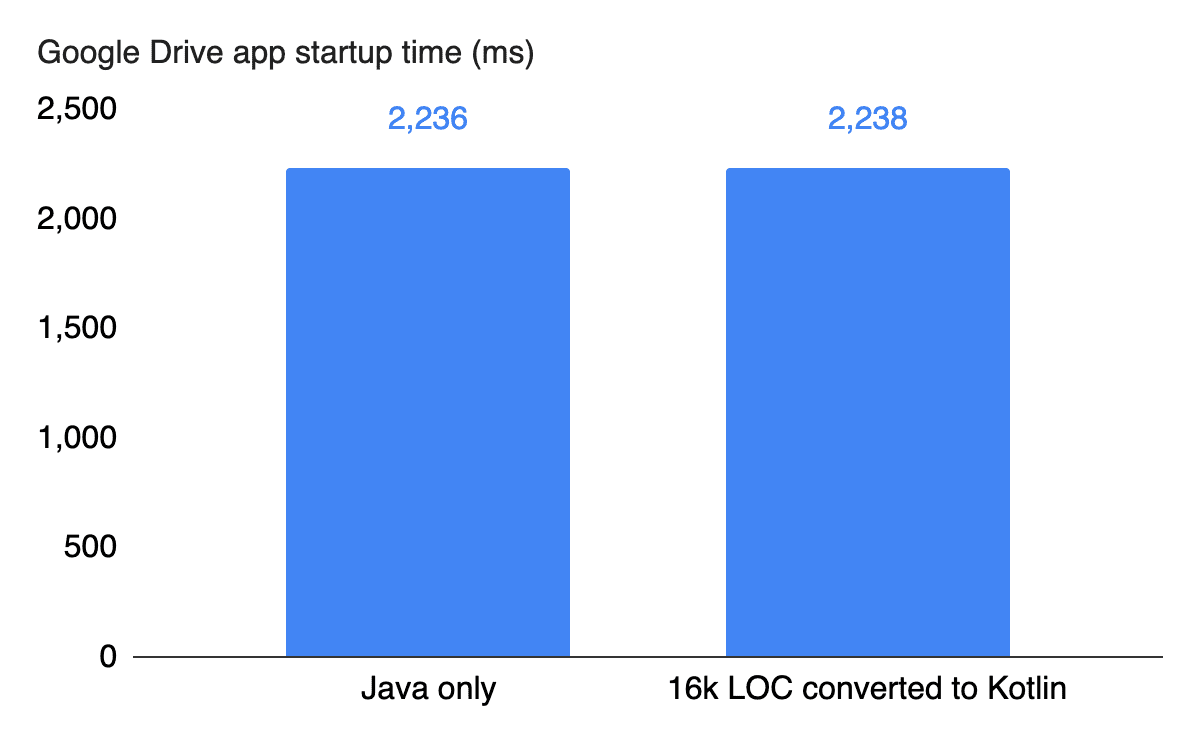
如图所示,使用 kotlin 并没有对性能造成实质的影响,而且在整个基准测试过程中,Google 团队也都没有观察到明显的性能差异,即使编译时间和编译后的代码大小略有增加,但都保持在 2% 之内,完全可以忽略不计。而得益于 kotlin 简洁的语法,团队的代码行却减少了大约 25%,也变得更易读和易维护。
还比较值得一提的是,使用 kotlin 时,我们也可以使用像 R8 这样的代码缩减工具,对代码进行进一步的优化。
误区二:Getters 和 setters 方法更耗时
因为担心性能下降,有些开发者会选择在类中直接使用 public 修饰字段,而不去写 getter 和 setter 方法,如下面这段代码,这里的 getFoo() 方法就是变量 foo 的 getter 函数:
1 | public class ToyClass { |
直接使用 tc.foo 获取变量显然已经破坏了面向对象的封装性,而在性能方面,我们在配备 Android 10 的 Pixel 3 上使用 Jetpack Benchmark 对 tc.getFoo() 与 tc.foo 两个方法进行了基准测试,该库提供了预热代码的功能,最终的稳定测试结果如下:
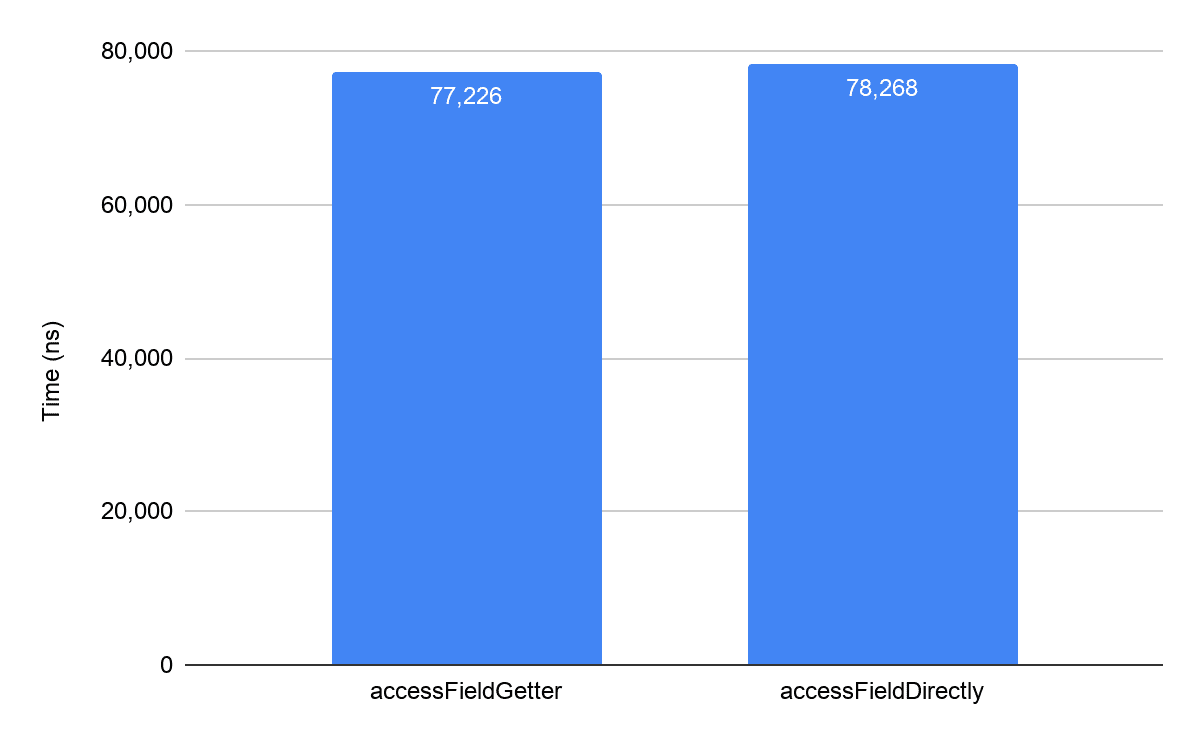
getter 方法的性能与直接 access 变量的性能也并没有多大差别,结果并不奇怪,因为 Android RunTime(ART)内联了代码中所有的 getter 方法,因此,在 JIT 或 AOT 编译后执行的代码是相同的,正因如此,在 kotlin 中即使我们默认需要使用 getter 或 setter 获得变量,性能也并不会有所下降,如果使用 Java,除非特殊需要,否则就不应该使用这种方式破坏代码的封装性。
误区三:Lambda 比内部类慢
Lambda(尤其是在引入 Stream API 的情况下)是一种非常方便的语法,可实现非常简洁的代码。如下这段代码,对对象数组的内部字段值求和,这里,使用了 Stream API 搭配 map-reduce 操作:
1 | ArrayList<ToyClass> array = build(); |
第一个 lambda 会将对象转换为整数,第二个 lambda 会将产生的两个值相加。
下面代码中,我们再将 lambda 表达式换成内部类:
1 | ToyClassToInteger toyClassToInteger = new ToyClassToInteger(); |
这里,有两个内部类:一个是 toyClassToInteger,它可以将对象转换为整数,第二个 SumOp 用来做求和运算。
从语法上看,第一个带有 lambda 的示例显然更优雅,也更易读。那么,性能差异又如何呢?我们再次在 Pixel 3 上使用了Jetpack Benchmark,也没有发现性能差异:
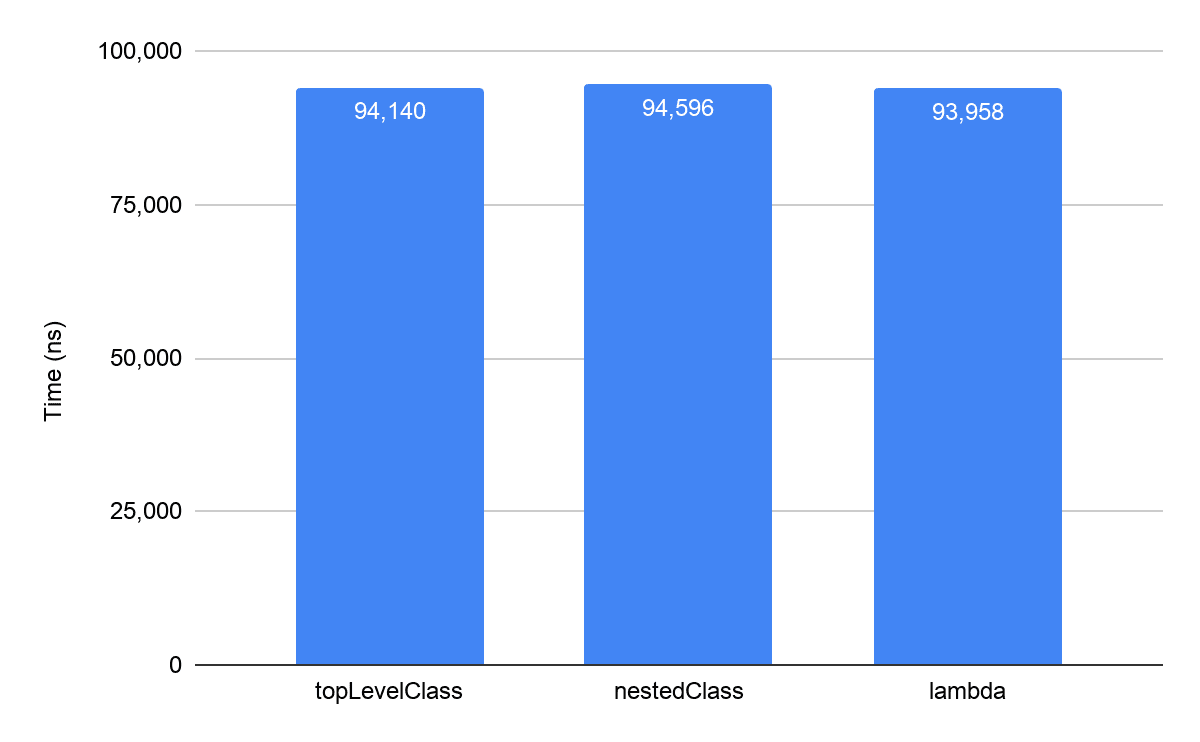
从图中可以看到,我们还定义了单独的外部(top-level)类一起来做比较,发现性能都没有什么差异,原因就是 lambda 表达式最终也会被转换为匿名内部类。因此,为了代码的简洁易读,在这种场景下 lambda 表达式就是第一选择。
误区四:对象分配开销过大,应该使用对象池
Android 内置了最先进的内存分配和垃圾回收机制,如下图所示,几乎每个版本的更新都在对象分配方面做各式各样的更新。
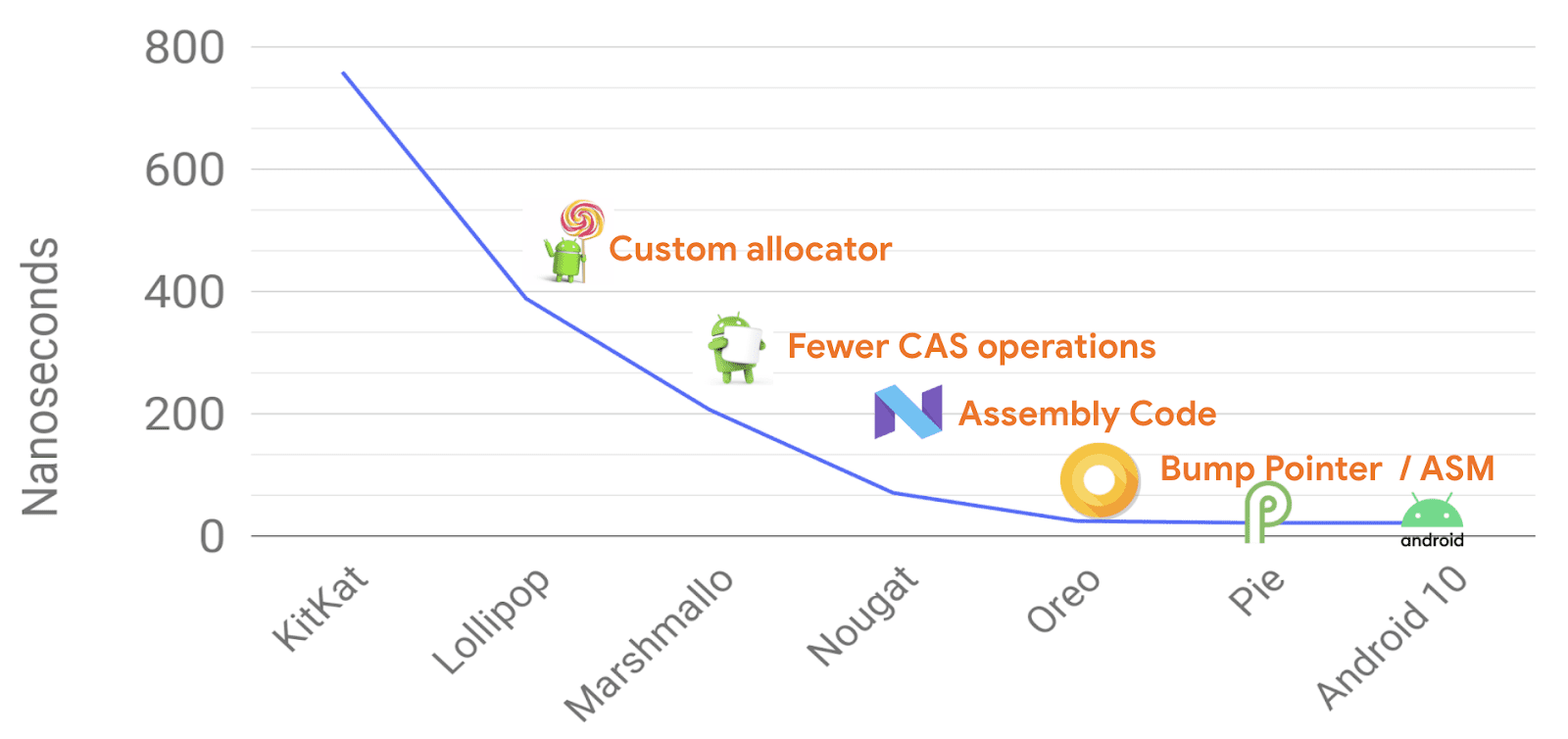
各个版本之间的垃圾收集性能都有显著的改善,如今,垃圾收集对应用程序的流畅已经几乎没有影响了。下图展示了 Google 官方在 Android 10 中对具有分代并发收集的对象收集所做的改进,新版本的 Android 11 中也有明显的改进。
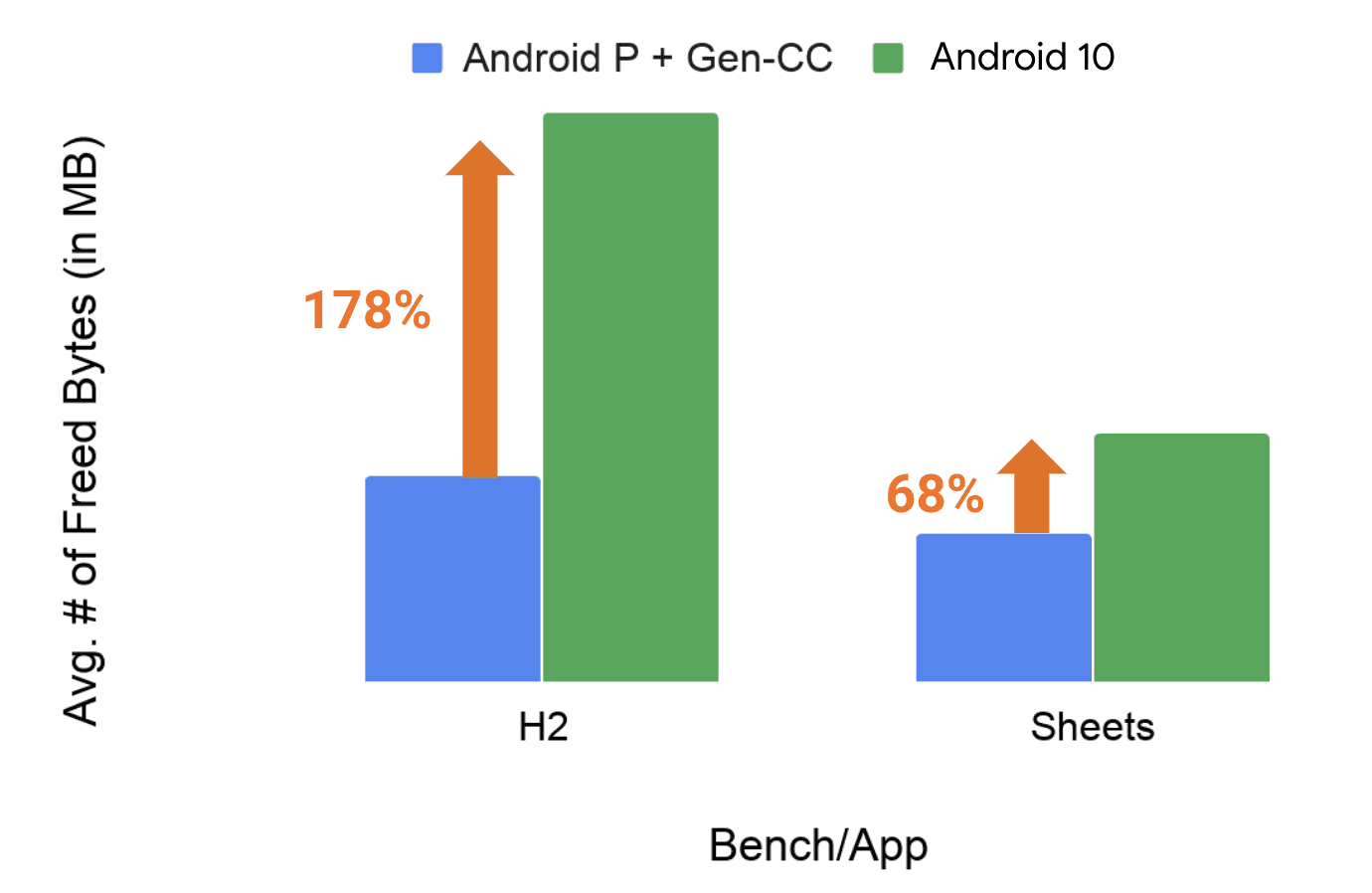
在GC基准测试(例如H2)中,吞吐量大幅提高了 170% 以上,而在实际应用(如 Google Sheets)中,吞吐量也提高了 68%。
如果认为垃圾收集效率低下并且内存分配负担很重,那么就相当于认为创建的垃圾越少,垃圾收集工作就越少,因此,代替每次使用时都创建新对象,我们可以维护一个经常使用的类型的对象池,然后从池中获取已创建的对象,如下:
1 | Pool<A> pool[] = new Pool<>[50]; |
这里省略了代码细节,大体就是就是定义了一个 pool,从 pool 中获取对象,然后最终释放。
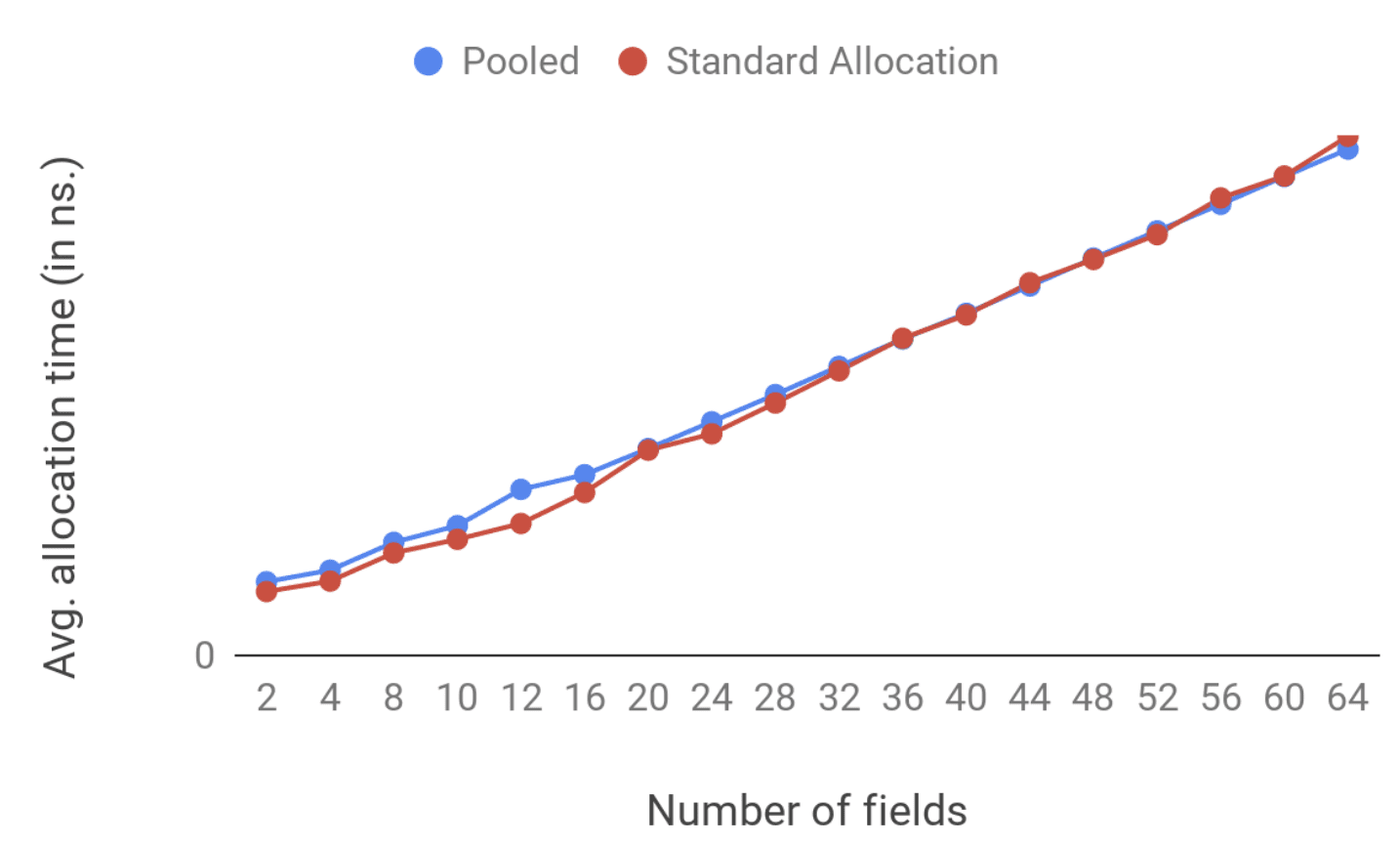
要测试这种场景,我们使用微基准测试(microbenchmark):从池中测试分配对象的开销,以及CPU的开销,来确定垃圾回收是否会影响应用程序的性能。
在这种情况下,我们依然可以在装有 Android 10 的 Pixel 2 XL 上循环运行了数千次分配对象的代码,因为对于小型或大型对象,性能可能会有所不同,我们还通过添加不同的字段来模拟不同的对象大小,最终的开销结果如下:
用于垃圾回收的 CPU 开销的结果如下:
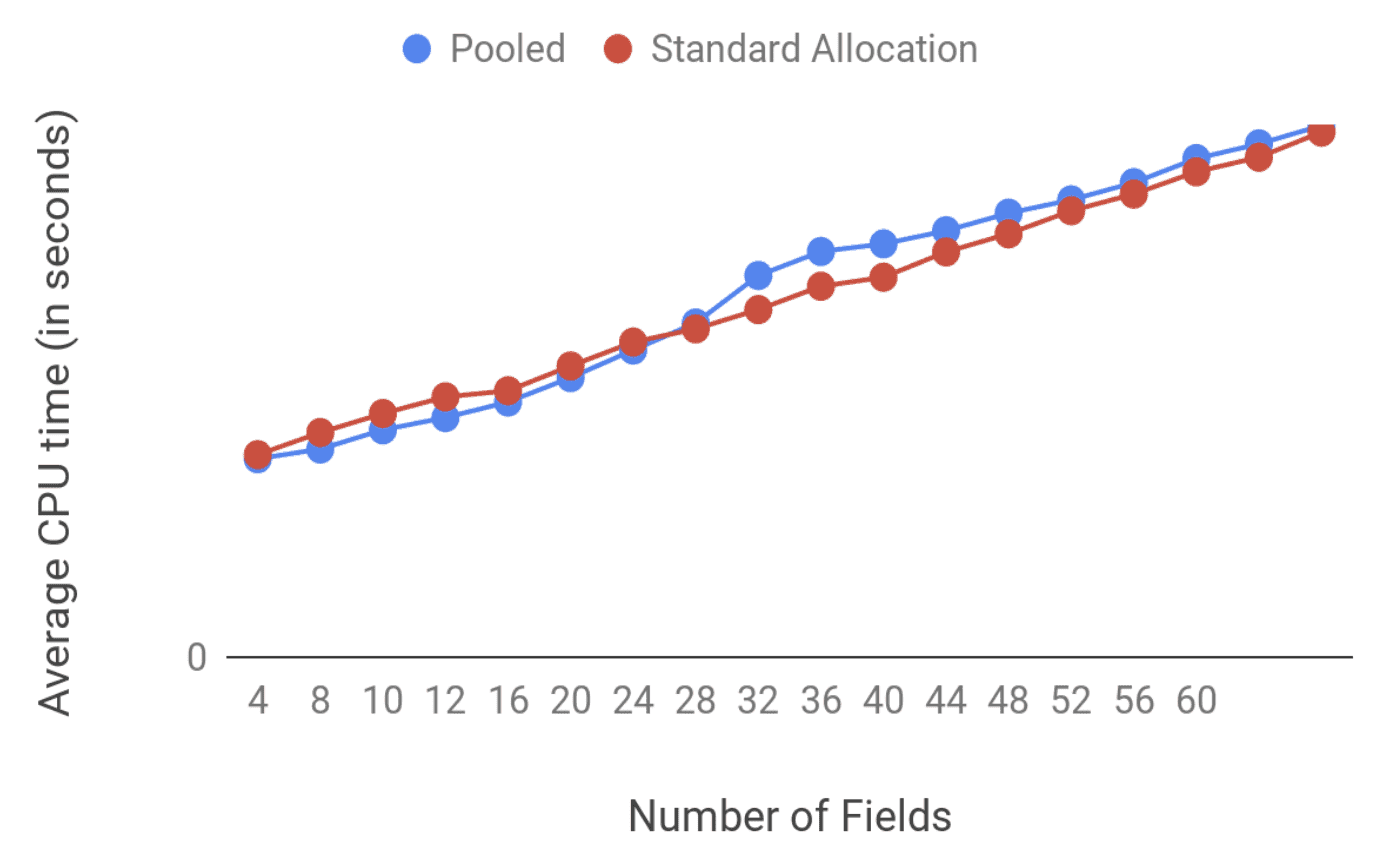
从图中可以看出,标准分配和池化对象之间的差异也很小,但是,当涉及到较大对象的垃圾回收时,池解决方案略微高一点。
这个结果并不意外,因为池化对象会增加应用的内存占用量,此时,应用突然占用了太多的内存,即使由于池化对象减少了垃圾回收调用的数量,每个垃圾回收调用的成本也更高,因为垃圾收集器必须遍历更多的内存才能确定哪些对象需要被收集,哪些对象需要保留。
那么,对象是否应该被池化,这还是主要取决于应用的需求。如果不考虑到代码复杂性,池化对象有如下缺点:
- 提高内存占用量
- 使对象存活变长
- 需要非常完善的对象池机制
但是,池的方法对于大并且耗时的对象分配可能确实是有效的,关键是要记住在选择方案之前进行充分的测试。
误区五:debug 模式下进行性能分析
在 debug 的同时对应用进行性能分析非常方便,毕竟,我们通常也是在 debug 模式下进行编码的,并且,即使 debug 应用中的性能分析不准确,也可以更快地进行迭代修改提高效率,然后事实是并没有。
为了验证这一误解,我们分析了 Activity 相关的常见操作过程过的测试结果,如下图:
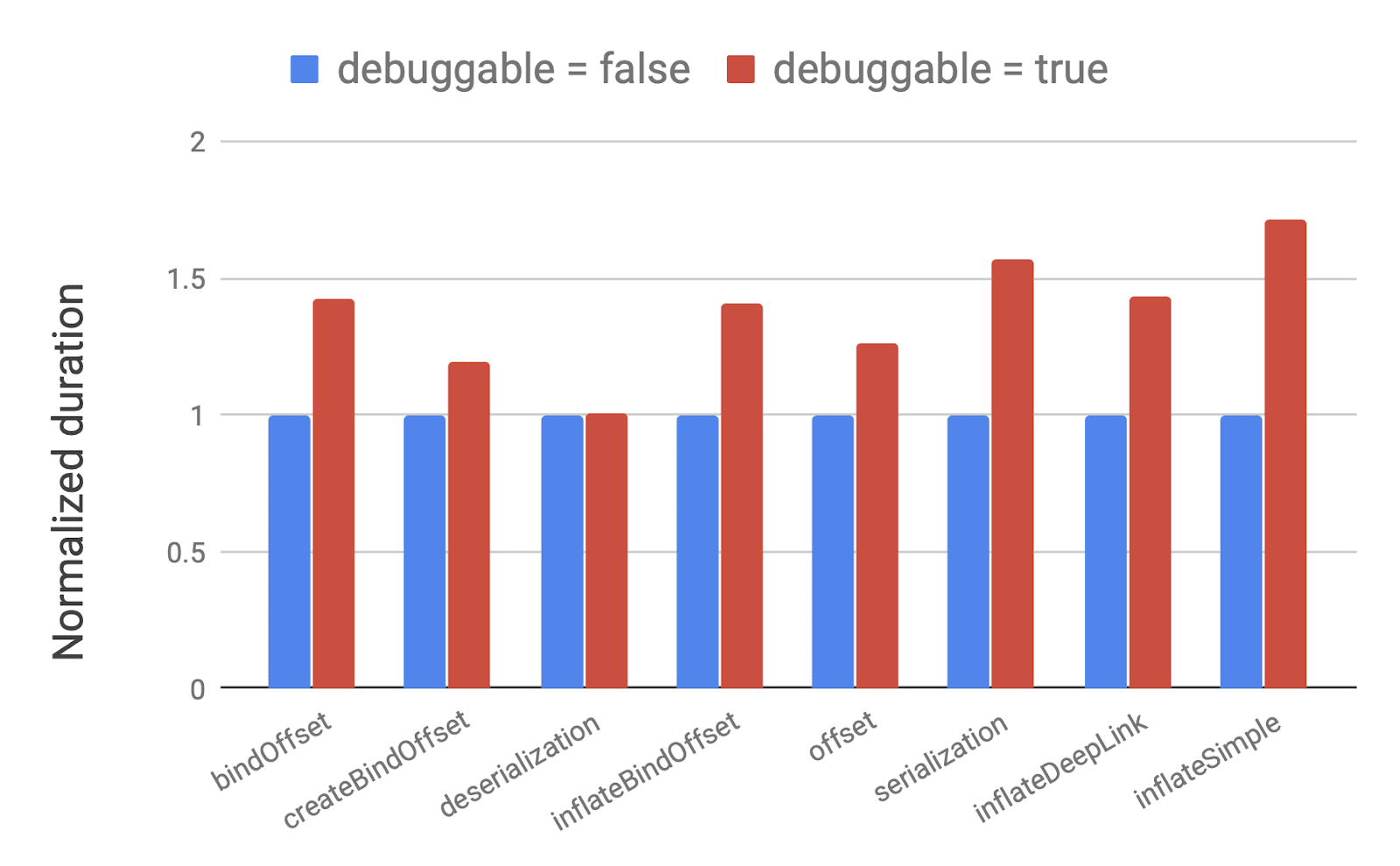
在某些测试(例如反序列化)中,debug 与否对性能没有影响,但是,有些结果却有 50% 甚至以上的差别,我们甚至发现结果速度可能会慢 100% 的例子,这是因为 runtime 在 debug 模式下时对代码几乎没有优化,因此与用户在生产设备上运行的代码有很大不同。
在 debug 模式下进行性能分析的结果是可能会误导优化方向,导致浪费时间来优化不需要优化的内容。
疑点
现在,我们需要有意识的逃避上述提到的五大误区,下面我们再来看一下一些日常开发中不太明显,但我们经常会有的疑惑的问题,事实结果可能也与我们想的大相径庭。
疑点1:Multidex:是否影响应用性能?
如今的 APK 文件越来越大,因为大型应用通常会超出 Android 限定的方法数量,从而使用 Multidex 方案打破传统的 dex 规范。
问题是,多少方法可以称之为多?而且如果应用包含大量 dex 是否对性能产生影响?很多时候我们也并不是因为应用太大,而是为了根据功能拆分 dex 文件来方便团队开发而使用 Multidex。
为了测试多个 dex 文件对性能的影响,我们使用了计算器应用,默认情况下,它只包含单个 dex 文件,我们可以根据其程序包边界将其拆分为五个 dex 文件,来根据功能部件模拟拆分。
首先,测试启动应用的性能,结果如下:

因此,拆分 dex 文件对此处并没有影响,对于其他应用,可能会因为某些因素而产生轻微的开销:应用程序的大小以及拆分方式。但是,只要合理地分割 dex 文件并且不添加成百个 dex 文件,对启动时间的影响应该不大。
接下来是 APK 的大小和内存消耗:
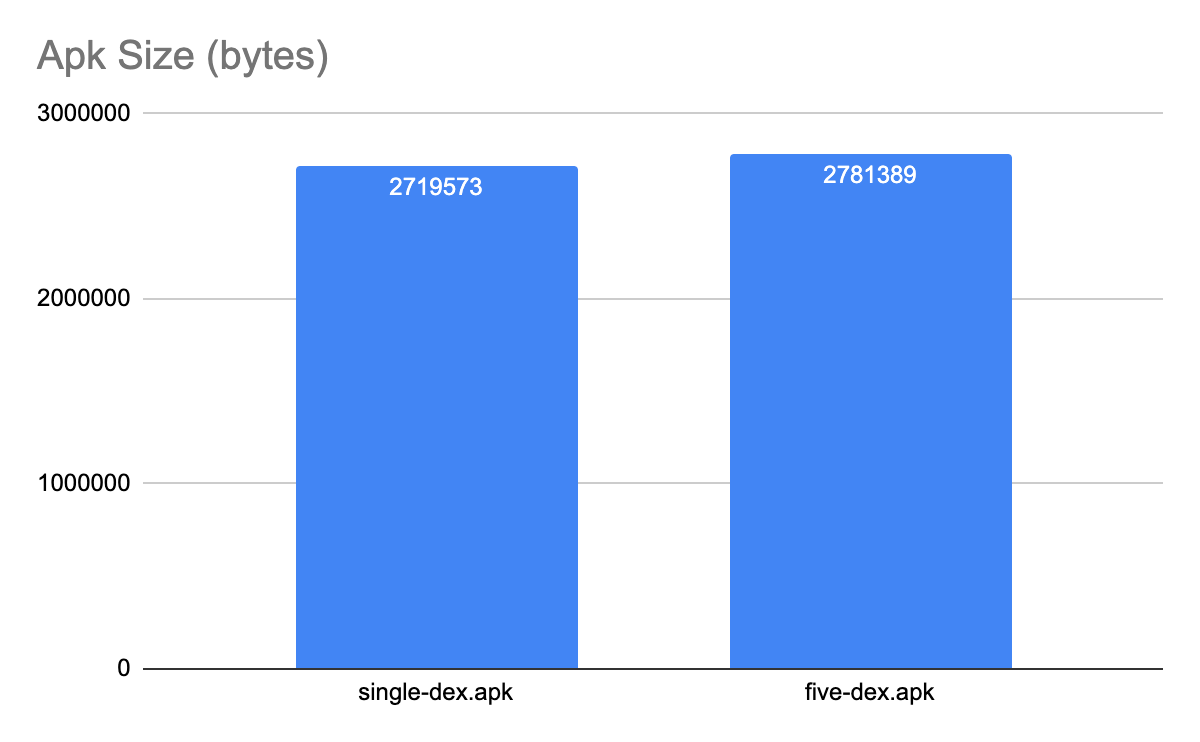
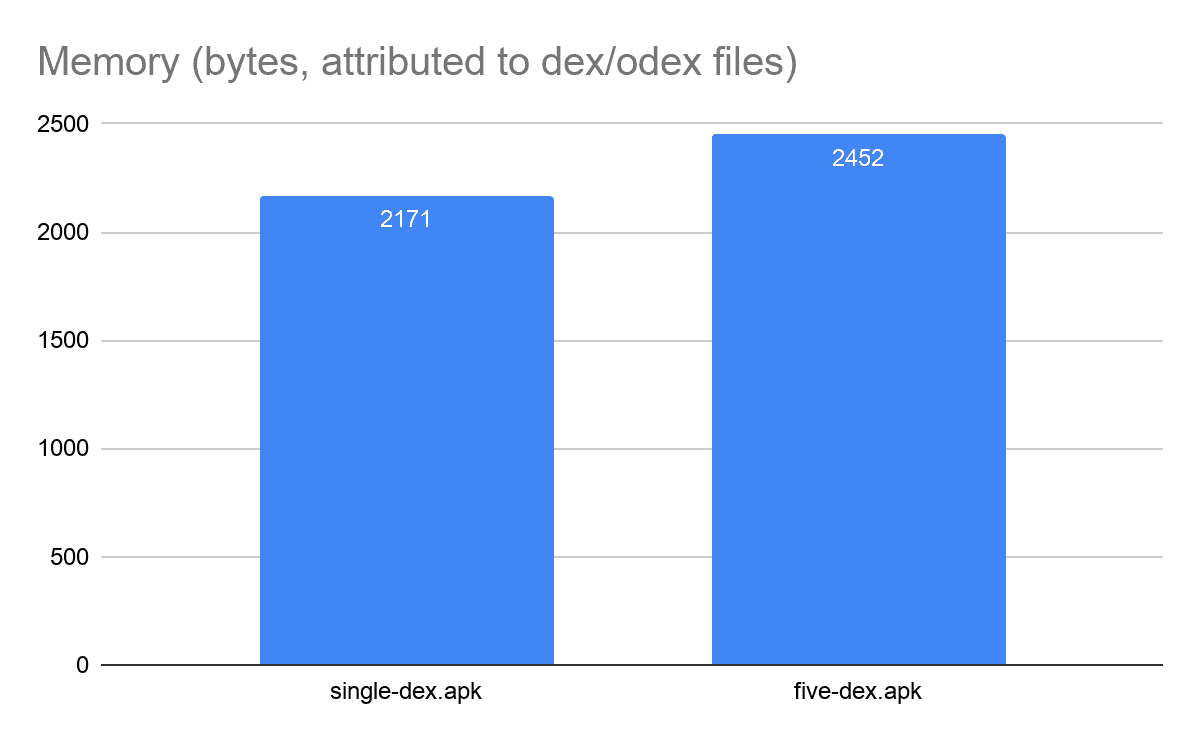
如图所示,APK 大小和应用的运行时内存占用量都略有增加,这是因为将应用程序拆分为多个 dex 文件时,每个 dex 文件都会有一些符号表和缓存表中的重复数据。
但是,我们可以通过减少 dex 文件之间的依赖关系来最大限度地避免这种情况,在这个案例中,并没有将 dex 包量化,我们可以使用 R8 和 D8 之类的工具合理分析项目结构并使用最小化的依赖关系,这些工具可以自动拆分 dex 文件,并帮助我们避免常见的错误,最大程度地减少依赖关系,如创建的 dex 文件数量不会超过指定的数量,并且不会将所有启动类都放置在主文件中。但是,如果我们对 dex 文件进行自定义拆分,请确保合理分析。
疑点2:无用代码
使用 ART 这样的即时编译器的好处之一就是可以在运行时分析代码,并对其进行优化。有一种说法是,如果解释器/ JIT系统没有对代码进行概要分析,就可能不会执行该代码。为了验证这一理论,我们检查了 Google 应用生成的 ART 配置文件,发现许多代码并没有被 JIT 做概要分析,这就表明许多代码实际上从未在设备上执行过。
有几种类型的代码可能无法剖析:
- 错误处理代码,希望它不会执行太多。
- 兼容性代码,并非在所有设备上都执行的代码,尤其是 Android 5 以上版本的设备。
- 不常用功能的代码。
但是,从结果分布来看,应用程序中还是会存在很多不必要的代码。R8 可以帮助我们快速,简便,免费地删除不必要的代码,来缩小这部分的开销。如果不这么做,我们也可以将应用打包成 Android App Bundle,这种格式只会使用特定设备所需的代码和资源来运行应用。
总结
本文,我们分析了 Android 性能优化的五大误区,但某些情况下数据的结果还并不清晰,我们需要做的就是在优化和修改代码之前尽量做好性能测试。
目前,已经有很多工具可以帮助我们分析评估如何优化应用了,如 Android Studio 中的 profilers,它也提供了电池和网络的监测功能。也可以用一些工具做更深入的探究,如 Perfetto 和 Systrace,这些工具会提供更加详细的功能,例如在应用启动或执行过程中发生的具体情况。
Jetpack Benchmark 摒弃了监测和基准测试的所有复杂操作,官方强烈建议我们在持续集成系统中使用它来跟踪性能,并查看应用在添加功能的行为,最后需要注意的一点是,不要在 debug 模式下分析应用性能。
关注公众号「Meandni」,及时阅读最新前沿技术动态,不至于落后时代。


